0 Abstract
Dataframes are a popular abstraction to represent, prepare, and analyze data. Despite the remarkable success of dataframe libraries in R and Python, dataframe operations face performance issues even on moderately large datasets. Moreover, there is significant ambiguity regarding dataframe semantics.
In this thesis, we discuss the implications of signature dataframe features including flexible schemas, ordering, row/column equivalence, and data/metadata fluidity, as well as the piecemeal, trial-and-error-based approach to interacting with dataframes. While most modern systems aim to scale dataframe workloads by changing properties of dataframes – or by requiring users to be proficient at distributed systems – we instead target supporting scalable dataframe operations without changing their semantics. This dissertation takes a ground-up approach towards scaling dataframe systems, starting with a formal dataframe data model and algebra, and ending with a reference implementation. This implementation, Modin, has already accumulated significant community support: over 6,000 GitHub stars and 1 million installs to date. This interest shows the need for systems that solve modern data science problems without changing semantics. Included in this thesis are several of our insights into how to build systems for data scientists and what aspects data scientists prioritize. We believe these insights were instrumental in unlocking the interest and support from the community in our open source work.
数据框架是表示、准备和分析数据的一个流行的抽象。尽管R和Python中的数据框架库取得了显著的成功,但数据框架操作即使在中等规模的数据集上也面临着性能问题。此外,关于数据框架的语义也存在很大的模糊性。
在这篇论文中,我们讨论了包括灵活的模式、排序、行/列等价和数据/元数据流动性在内的标志性数据框架特征的影响,以及与数据框架互动的零碎的、基于试验和错误的方法。
虽然大多数现代系统旨在通过改变数据框架的属性来扩展数据框架的工作负载--或者要求用户精通分布式系统--但我们的目标是支持可扩展的数据框架操作,而不改变其语义。
本论文对数据框架系统的扩展采取了从头开始的方法,从正式的数据框架数据模型和代数开始,到最后的参考实现。这个实现,即Modin,已经积累了大量的社区支持:至今已有超过6000个GitHub星级和100万个安装。这种兴趣显示了对解决现代数据科学问题而不改变语义的系统的需求。在这篇论文中包括了我们对如何为数据科学家建立系统以及数据科学家优先考虑哪些方面的见解。我们相信,这些见解对于激发社区对我们的开源工作的兴趣和支持是非常重要的。
1 Introduction
传统的数据分析工具基于单线程、单机,开始不能满足数据规模增长带来的数据分析需求。大数据的分析工具的实现基于计算图和惰性执行,可以应对大规模数据计算的需要;然而data scientists更偏爱evaluation-based计算工具,如pandas,它们的交互更方便
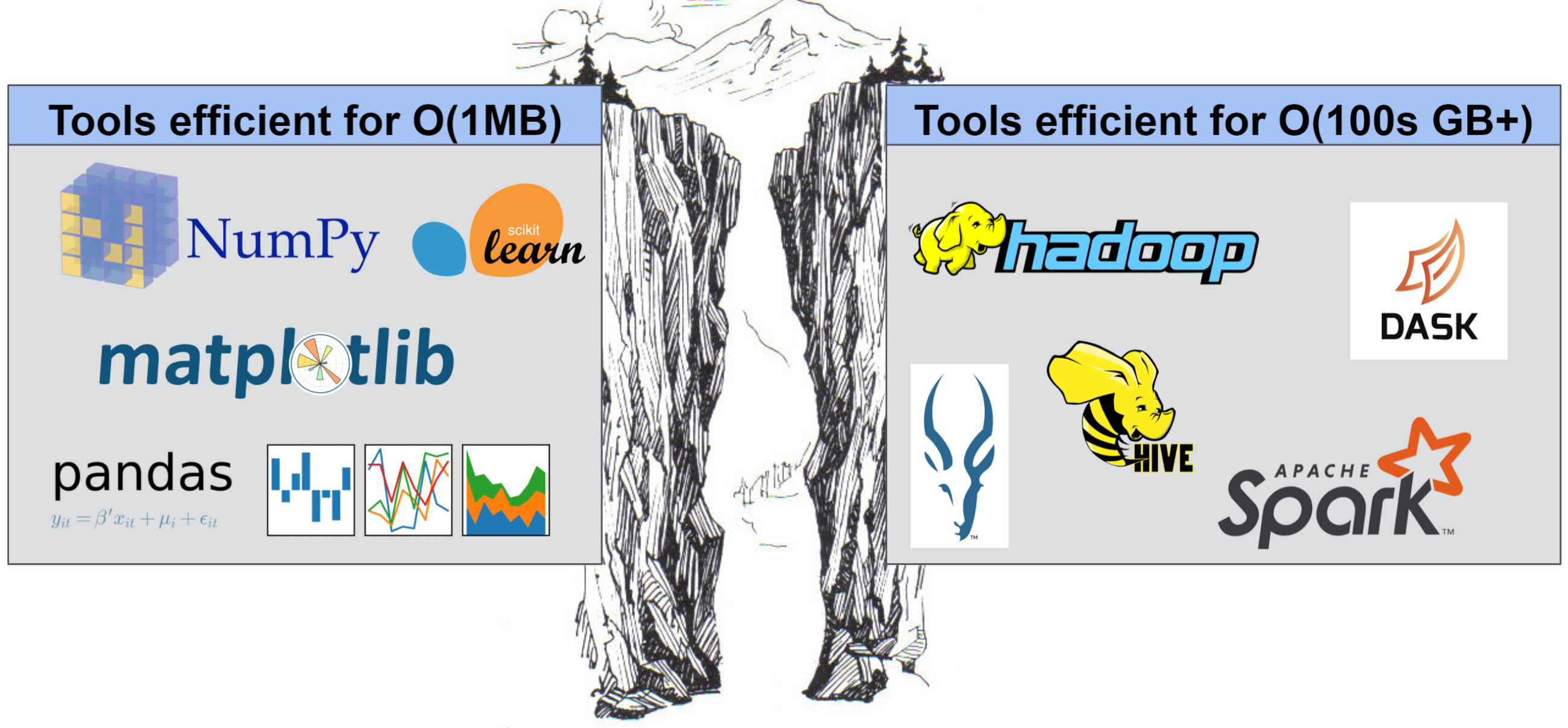
我们的目标是保持左侧工具的易用性,同时提供右侧工具的可扩展性优势。
数据帧是表示、准备和分析数据的流行抽象。然而,尽管熊猫和类似的数据帧库在R中取得了显著成功,但即使在中等大小的数据集上,数据帧也面临性能问题。此外,数据帧语义存在很大的模糊性。在本论文中,我们提出了可扩展数据帧系统的愿景和路线图。我们提出基于坚实理论基础的熊猫等现有数据帧库的演变,这些库可以在不牺牲语义的情况下扩展到现代数据量。
在第2章中,我们深入研究了数据帧用户行为的细微差别。我们详细探讨了这种行为可能会如何影响数据帧系统的性能。数据帧的使用具有某些特征,这些特征与关系数据库等其他可扩展数据处理工具的用户不同。例如,数据帧用户以增量、迭代和交互式方式构建查询。仅此一项就提出了关系数据库中不存在的多个挑战,特别是在查询规划和查询优化方面。
在第3章中,我们提出了数据帧的候选数据模型和代数,为本文其余部分奠定了理论基础。虽然数据帧在关系代数和线性代数中都有根,但它们既不是表也不是矩阵。例如,数据帧像矩阵一样有序,但支持多种数据类型,如关系数据库。我们将利用相似性和差异,使我们能够在数据框架代数中定义关系和线性代数运算符。深入探讨了支持数据帧独特属性的挑战的细微差别,并为未解决的数据框架挑战提供了一套潜在的解决方案。
在第4章中,我们介绍了数据帧系统的架构和设计要求。本章不提供实现,而是提出了其他系统可以实现的架构,以获得数据帧代数和数据模型的全部好处。本章详细探讨了可能会给这种实现带来哪些考虑因素。本章的重点是代数运算符的细微差别和实现考虑因素。
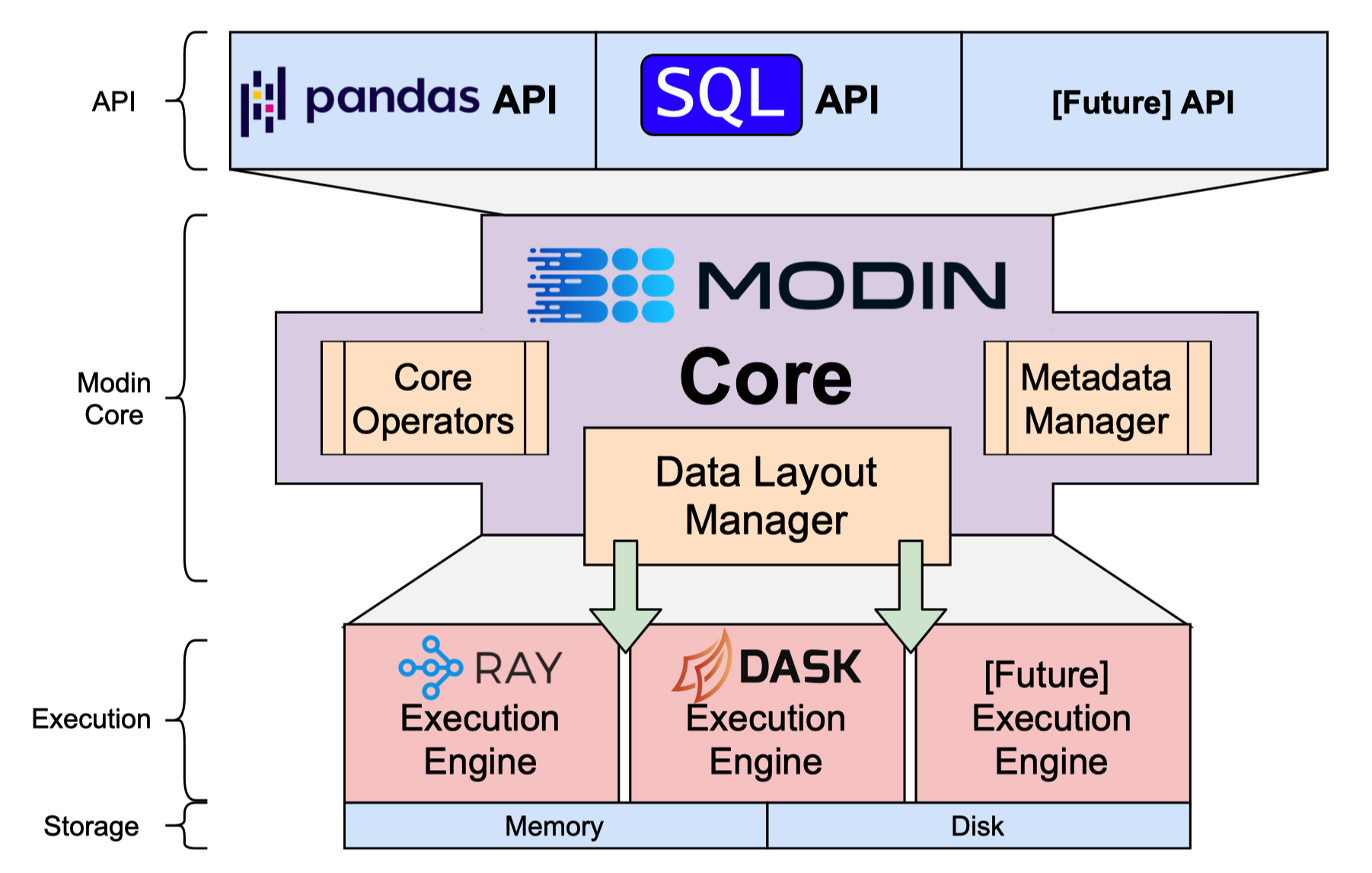
第5章介绍了我们的参考实现Modin以及我们用于确定此实现中的最佳并行性的规则。Modin的架构如图1.2所示,旨在支持多个执行后端。这一设计决策源于在所有环境中支持数据科学的目标,以便数据科学家可以在具有相同结果的不同操作环境中使用相同的Modin笔记本。Modin通过将熊猫运算符转换为我们在第3章和第4章中讨论的基本代数实现,向用户公开了熟悉的熊猫API。我们还讨论了低级实施决策,并进一步关注我们如何在Modin中管理元数据。每个运算符都以特定的方式操作元数据,我们在第5章中对此进行了解释。我们讨论了如何克服数据帧的分布式实现方面的许多挑战,包括将某些元数据保持在用户附近(例如行和列标签),同时试图使标签不可避免地作为数据操作时使标签接近数据。Modin在开源社区中的影响可以通过GitHub星数(6000+)和安装次数(超过100万)[73]来衡量。Modin的影响表明,非常需要保留语义的分布式数据帧实现。
第六章专门评估Modin的不同组件,并与已建立的数据处理系统进行比较。我们首先对Modin与Dask Dataframe[30]和Koalas(Spark)[63]进行比较。此功能分析着眼于每个实现涵盖了多少熊猫API。随后有一个讨论此处评估的每个实现(Modin、Dask Dataframe和Koalas)的架构的局限性,重点是每个实现如何更改以改善熊猫API的覆盖范围。在这次讨论之后,我们研究了Modin在各种工作负载和查询中的表现。我们将Modin与Dask Dataframe和考拉进行比较,并使用熊猫作为基线。在各种工作负载和查询类型上,Modin比考拉快100倍,比Dask数据帧快50倍,比熊猫快50倍。通过这些指标,我们研究了Dask Dataframe和Spark如何利用Modin中的一些架构决策来提高性能。
在第7章中,我们对处理数据帧用户一些更独特行为的架构和潜在优化进行了案例研究。我们提出了一种称为机会主义评估的方法,该方法利用用户的思考时间在数据帧语句上取得进展。传统上,系统会懒洋洋地排队操作和执行查询,这允许查询规划和查询优化,但让CPU闲置于用户花费思考的周期。机会主义评估利用这段思考时间来确保CPU正在努力取得成果,以节省数据科学家的时间。确定利用思考时间的方法的潜在功效的第一步是确定用户实际花在思考上的时间。我们分析了来自Data 100学生语料库中的笔记本痕迹,发现在笔记本的关键位置通常会花费大量思考时间,通常围绕着难以计算的任务。然后,我们设计了一种方法来利用这段思考时间,最终比懒惰评估快8倍。这里的结果表明,传统的计算范式在交互式环境中不是最佳的,机会主义评估是实现高效交互式数据科学的良好开端。
第8章讨论了我们建立一个成功的开源社区的经验。我们根据我们做对和错的事情提供一套建议。重点是作为一名研究生,这样做会发生什么,以及它可能会如何影响研究生院的其他方面。
2 The Requirements of a Dataframe System
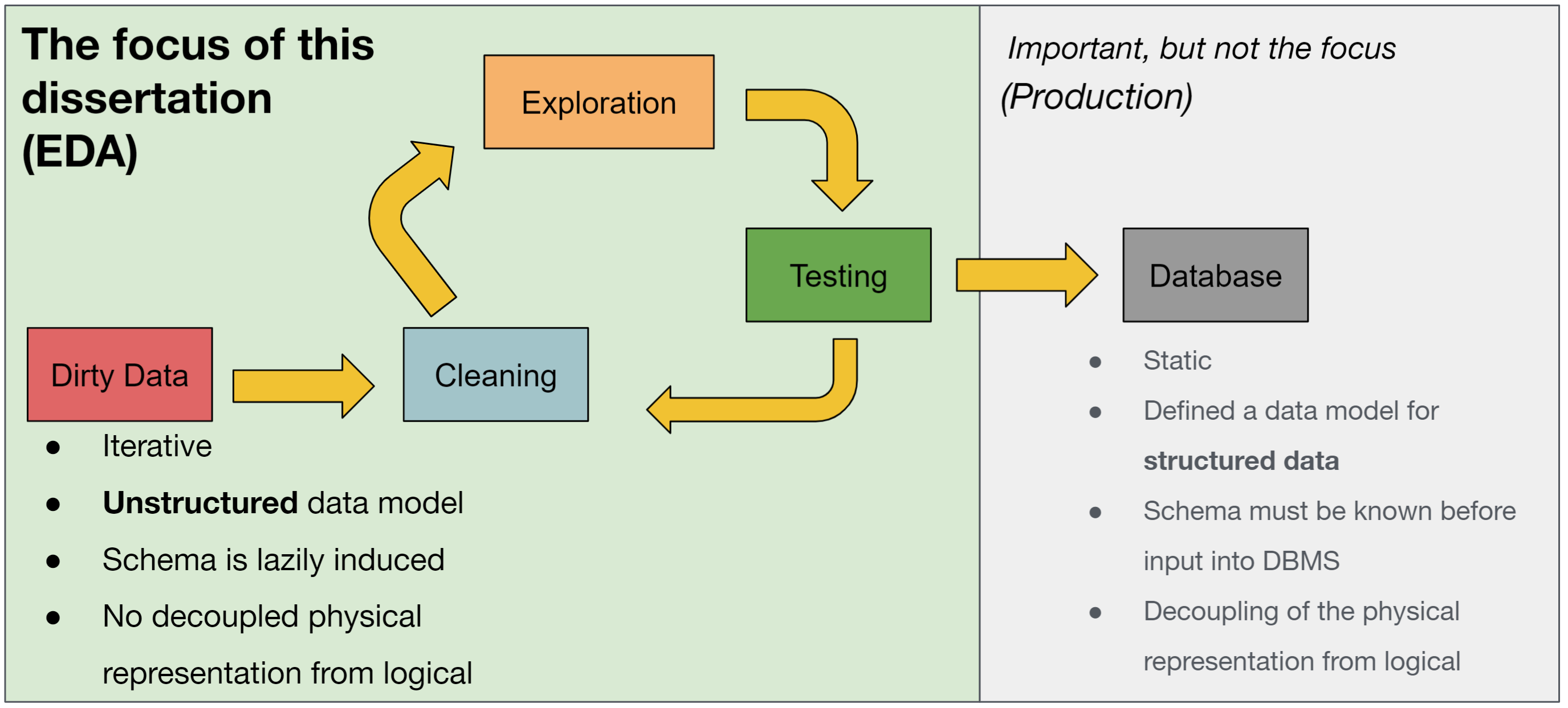
EDA: Exploratory Data Analysis
Dataframes provide a functional interface that is more tolerant of unknown data structures and well-suited to developer and data scientist workflows
dataframe的优势
• an intuitive data model that embraces an implicit ordering on both columns and rows and treats them symmetrically;
• a query language that bridges a variety of data analysis modalities including relational (e.g., filter, join), linear algebra (e.g., transpose), and spreadsheet-like (e.g., pivot) operators;
• an incrementally composable query syntax that encourages easy and rapid validation of simple expressions, and their iterative refinement and composition into complex queries; and
• native embedding in a host language such as Python with familiar imperative semantics.
两个常规的数据分析例子,拿到数据后
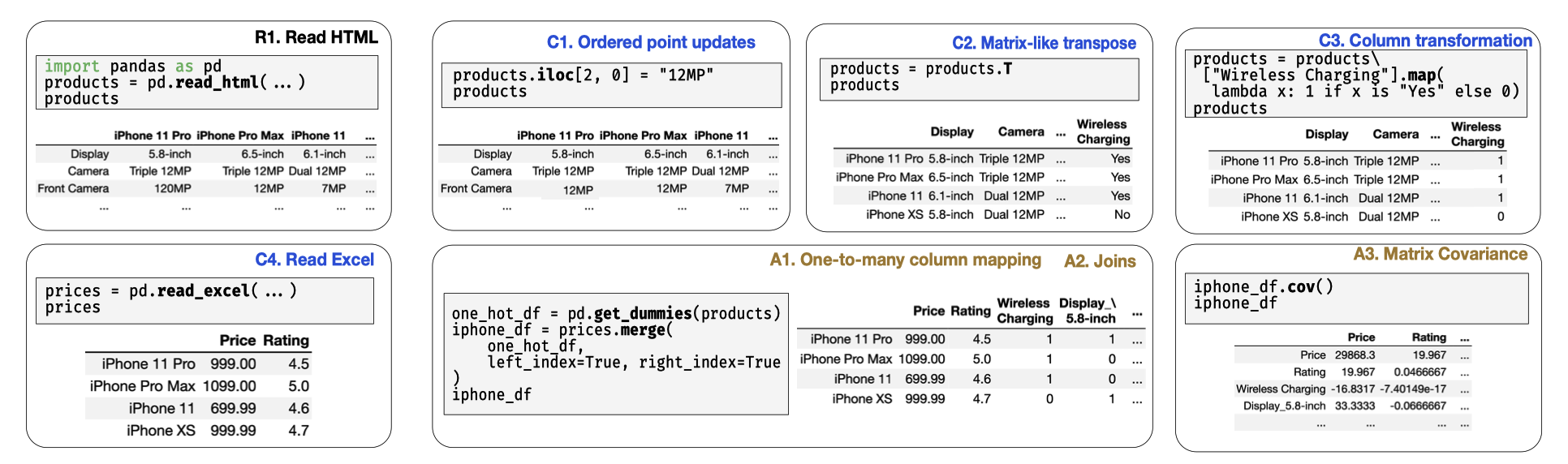
This interactive session-based programming model for dataframes creates novel challenges for overall system performance and imposes additional constraints on query optimization. For example, operator reordering is often not beneficial when the results are materialized for viewing after every statement. At the same time, dataframe query development sessions are bursty, with ample think time between issuance of statements, and are tolerant of incomplete results as feedback as long as the original goals of experimentation and debugging are met, offering new opportunities for query optimization. In this section, we discuss new challenges and opportunities in query optimization arising from the interactive and incremental trial-and-error query construction of a typical user.
这种基于会话的交互式数据帧编程模型为整个系统的性能带来了新的挑战,并对查询优化施加了额外的限制。例如,当每条语句后的结果都被物化以供查看时,运算符的重新排序往往是不可取的。同时,数据框架查询的开发过程是突发性的,在发布语句之间有充足的思考时间,而且只要达到最初的实验和调试目标,就能容忍不完整的结果作为反馈,这为查询优化提供了新的机会。在这一节中,我们将讨论典型用户的交互式和增量式试错查询构建所带来的查询优化方面的新挑战和机会。
惰性反馈和即时反馈的对比
例如,考虑两个交换运算op1和op2。假设用户提交语句x = df.op1(),后跟y = x.op2()。在急切的评估中,x将在y开始执行之前完全实现,即使x再也没有使用过。使用df.op2().op1()计算y,但使用x的实例化版本通常更有益。在惰性评估中,执行将推迟到显式请求,因此创建y的表达式可以优化为运行df.op2().op1()。这种方法的缺点是,用户必须显式请求y,才能意识到x中存在潜在的错误。
In addition to challenges around enabling immediate feedback, query optimization is further complicated by the need to frequently evaluate and display results for intermediate subexpressions (i.e., the results of statements) over the course of a session (see also Section 2.4).
除了围绕实现即时反馈的挑战之外,查询优化还因为需要在会话过程中频繁地评估和显示中间子表达式(即语句的结果)而变得更加复杂(也见第2.4节)。
However, since user statements often build on others, we can jointly optimize across these statements and resulting sub-expressions, sharing the work as much as is feasible. Further, since users commonly return to old statements to try out new exploration paths, we can leverage materialization to avoid redundant reexecution. We discuss these two ideas next.
然而,由于用户的语句经常建立在其他语句之上,我们可以在这些语句和由此产生的子表达式之间进行联合优化,尽可能地分担工作。此外,由于用户经常返回旧的语句来尝试新的探索路径,我们可以利用物化来避免多余的重新执行。我们接下来讨论这两个想法。
3 Dataframe Theoretical Foundation
Dataframe的概念最早1990在S语言中被引入,它比矩阵更灵活,矩阵假设所有的元素相同
J. Chambers, T. Hastie, and D. Pregibon. “Statistical Models in S”. In: Compstat. Ed. by Konstantin Momirovi´c and Vesna Mildner. Heidelberg: Physica-Verlag HD, 1990, pp. 317–321. ISBN: 978-3-642-50096-1.
R编程语言是S的一个开源实现,有一些额外的创新,于1995年首次发布,2000年发布了一个稳定版本,并在统计学界获得了即时的采用。最后,在2008年,Wes McKinney开发了pandas,努力将具有类似R语义的数据框架功能带到Python中,正如我们在介绍中所描述的,Python现在已经非常流行。