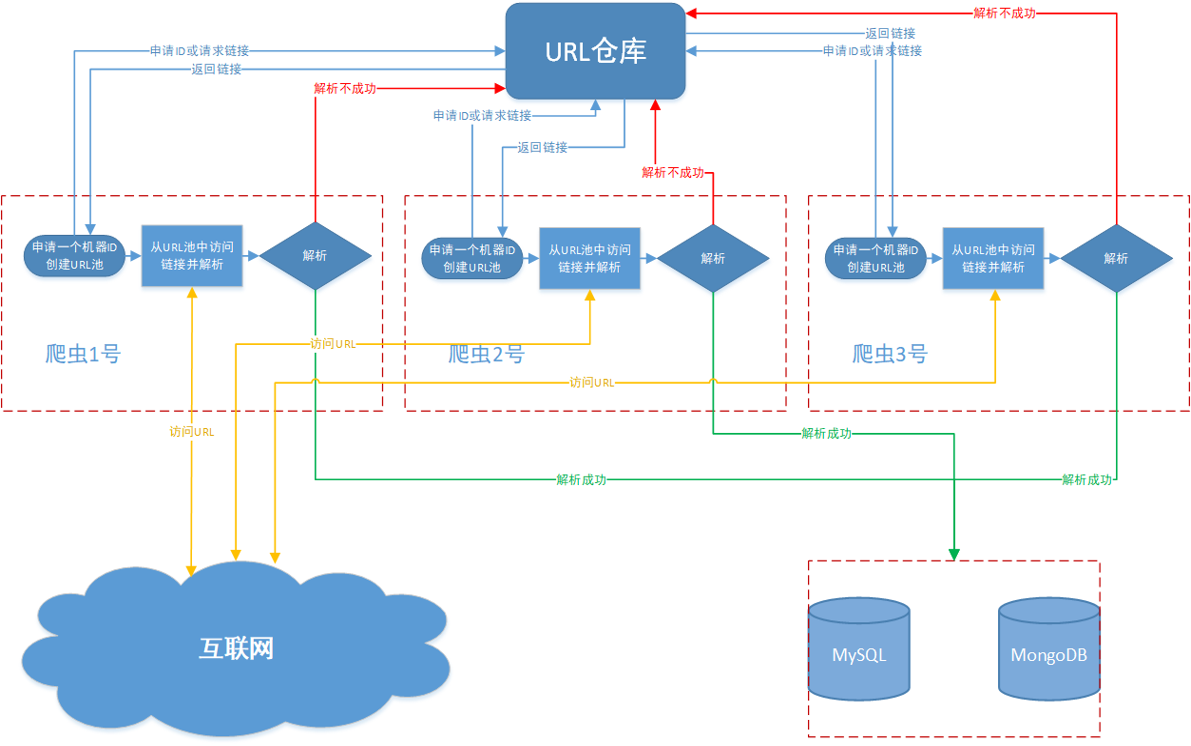
简易分布式爬虫由两部分组成:中央url仓库和爬虫机器。中央仓库动态维护url队列,对已爬取和未爬取的url做标记,负责做分发任务和对抓取的数据进行校验;爬虫机器向中央仓库请求未爬取的链接,并动态添加新url
[TOC]
统一安装软件
Ubuntu16服务器执行以下操作,分布式时可以通过Xshell在多服务器同时执行。或者将此内容设置为服务器的初始化脚本
sudo apt update
sudo apt install lrzsz 方便Xshell拽托上传文件
wget https://repo.continuum.io/archive/Anaconda2-4.3.1-Linux-x86_64.sh
sudo bash Anaconda2-4.3.1-Linux-x86_64.sh 安装时,需要选择将Anaconda加入环境变量
sudo chmod 777 -R anaconda2/
conda install MySQL-python
conda install pymongo
MongoDB配置
MongoDB安装
"#"注释掉bindIp,允许远程MongoDB远程连接
sudo vi /etc/mongod.conf
net:
#bindIp: 127.0.0.1
port: 27017
security:
authorization: "enabled"
创建管理员
use admin
db.createUser(
{
user: "rec",
pwd: "****",
roles: [ { role: "userAdminAnyDatabase", db: "admin" } ]
}
)
创建数据库绑定用户
use admin
db.auth("rec","gogo1357A*")
use db2
db.createUser(
{
user: "rec",
pwd: "****",
roles: [
{ role: "readWrite", db: "db2" },
{ role: "read", db: "db2" }
]
}
)
导出\导入数据
mongoexport --host 127.0.0.1 --port 27017 --db db2 -u rec -p "****" --collection items --out items.json
mongoimport --host 127.0.0.1 --port 27017 --db db2 -u rec -p "****" --collection items --file items.json
mongo rec:gogo1357A*@127.0.0.1:27017/db2 --shell query.js > result.txt
拷贝数据库到本地
db.copyDatabase("fromdb", "todb", "fromhost:27017", username, password) username, password可缺省
运行程序
Xshell多服务器同时终止进程,或开始进程
ps -ef | grep music | grep -v auto | cut -c 9-15 | xargs kill -s 9 同时终止名称中带umusic的进程
nohup python -u music.py > music.log 2>&1 & 带日志统一运行music.py
nohup python -u music.py >/dev/null 2>&1 & 不带日志统一运行music.py
注:名字中包含music、不包含auto的进程;cut截取参数中9-15即pid;xargs引入参数,-s 9强行执行
MySQL相关
修改mysql默认配置
防止单机睡眠时间太长,默认8h,现设置为50s
set global wait_timeout=50;
set global interactive_timeout=50;
MySQL表items
- items_id 专辑号,也即专辑链接。(替换最后一项
https://music.douban.com/subject/27030004/, 即为专辑链接) - status 状态码
- comments_num 为专辑评论数目,时间截至到2017/05/17
- machine_id
为正在爬取当前链接的标记,0表示无,其他为id号。(程序执行时,程序向服务器随机请求)
示例
| item_id | comments_num | status | machine_id |
|---|---|---|---|
| 1394541 | 0 | 0 | 532 |
| status=-1 | 404,无出度或评论 | ||
| status=0 | 等待抓取 | ||
| status=1 | 抓取完成 | ||
| status=2 | 正在抓取 | ||
| status=3 | 评论信息手机完毕 | ||
| status=4 | 评论信息正在搜集 |
MySQL表users
- user_id 用户id,也即用户链接。(替换最后一项
https://www.douban.com/people/gongyanc/, 即为用户连接) - user_id_num 用户数字id,-1代表用户已注销或者无头像。(替换最后一项
https://img1.doubanio.com/icon/ul138762062.jpg
ul138762062.jpg为uluser_id_num.jpg,即为头像) - user_title 用户名
- status 状态码,与items表相同
- comments_num 用户评论数目,时间截至到2017/05/17
- machine_id
机器码,0表示无,其他为id号。(程序执行时,程序向服务器随机请求)
示例
| user_id | user_id_num | user_title | comments_num | status | machine_id |
|---|---|---|---|---|---|
| zylovenic | 4190923 | 四季末的唱游 | 11 | 0 | 532 |
MySQL表comments
- item_id 专辑id
- user_id 用户id
- rating 评分。(“立荐”,“推荐”, “还行”, “较差”, “很差”, “空”
分别对应5,4,3,2,1,空) - comment 评论
- comment_time 评论时间
示例
| item_id | user_id | rating | comment | comment_time |
|---|---|---|---|---|
| 1394540 | 42864633 | 力荐 | 哈利赫敏跳舞的音乐 | 2010-11-24 |
MySQL初始化代码
CREATE TABLE `items` (
`item_id` INT(11) NOT NULL,
`status` INT(11) NOT NULL,
`comments_num` INT(11) NOT NULL,
`machine_id` INT(11) NOT NULL,
PRIMARY KEY (`item_id`)
)
COLLATE='utf8_unicode_ci'
ENGINE=InnoDB
;
CREATE TABLE `users` (
`user_id` VARCHAR(50) NOT NULL COLLATE 'utf8_unicode_ci',
`user_id_num` INT(11) NOT NULL,
`user_title` VARCHAR(50) NOT NULL COLLATE 'utf8_unicode_ci',
`status` INT(11) NOT NULL,
`comments_num` INT(11) NULL DEFAULT NULL,
`machine_id` INT(11) NULL DEFAULT NULL,
PRIMARY KEY (`user_id`)
)
COLLATE='utf8_unicode_ci'
ENGINE=InnoDB
;
CREATE TABLE `comments` (
`item_id` INT(11) NOT NULL,
`user_id` VARCHAR(50) NOT NULL COLLATE 'utf8_unicode_ci',
`rating` VARCHAR(50) NOT NULL COLLATE 'utf8_unicode_ci',
`comment` TEXT NULL COLLATE 'utf8_unicode_ci',
`comment_time` DATE NULL DEFAULT NULL,
PRIMARY KEY (`item_id`, `user_id`),
INDEX `user_id` (`user_id`),
CONSTRAINT `items_users_ibfk_1` FOREIGN KEY (`item_id`) REFERENCES `items` (`item_id`),
CONSTRAINT `items_users_ibfk_2` FOREIGN KEY (`user_id`) REFERENCES `users` (`user_id`)
)
COLLATE='utf8_unicode_ci'
ENGINE=InnoDB
;
MySQL查询
select count(*) from items where status =3;
update items set status = 1 where status = 3;
UPDATE SET status = 2, machine = 1 WHERE item_id = (SELECT i.item_id FROM (SELECT * FROM items WHERE status = 0) i WHERE i.status = 0 LIMIT 1);
SELECT * FROM items WHERE status = 0 and item_id >= ((SELECT MAX(item_id) FROM items)-(SELECT MIN(item_id) FROM items)) * RAND() + (SELECT MIN(item_id) FROM items) LIMIT 1
INSERT OR IGNORE into items values(26920951,0);
update items set `image`=replace(image, 'spic', 'lpic') WHERE item_id=1394555;
拷贝数据库到本地
mysql>CREATE DATABASE `newdb` DEFAULT CHARACTER SET UTF8 COLLATE UTF8_GENERAL_CI;
#mysqldump db1 -u root -ppassword --add-drop-table | mysql newdb -u root -ppassword
#mysqldump db1 -u root -ppassword --add-drop-table | mysql -h 192.168.1.22 newdb -uroot -ppassword
其他
正则匹配
<a href="https://music.douban.com/subject/27030004/comments/" target="_self">全部 1345 条</a>
u"(?<=target=\"_self\">全部 )\d+(?= 条</a>)", 此处用u或者r, u代表utf8, r代表不用转义字符
处理json文件
#coding:utf-8
import json
tweets = []
for line in open('items.json', 'r'):
tweets.append(json.loads(line))
with open('items.json', 'r') as f:
data = json.load(f)
print data
爬虫代理
#encoding=utf8
import urllib
import socket
socket.setdefaulttimeout(3)
f = open("proxy")
lines = f.readlines()
proxys = []
for i in range(0,len(lines)):
ip = lines[i].strip("\n").split("\t")
proxy_host = "http://"+ip[0]+":"+ip[1]
proxy_temp = {"http":proxy_host}
proxys.append(proxy_temp)
url = "http://ip.chinaz.com/getip.aspx"
for proxy in proxys:
try:
res = urllib.urlopen(url,proxies=proxy).read()
print res
except Exception,e:
print proxy
print e
continue